Engineering an AI App
Key principles to guide engineers building AI-first applications
When I started developing AI apps, it was still a new concept for many developers. Since then, I've developed many AI-first apps, including:
- New Email: a tool to create templates using natural language (new.email)
- Open-source: worked extensively with LangChain and became an active collaborator
- Written content: wrote a blog post about AI chat with LangChain Pinecone Memory
- Public projects: built open-source projects like GitGlean and Bugdet
While so much is still changing, the underlying issues and engineering challenges have stabilized. In this post, I'll share my core learnings to guide you to build robust AI apps.
Determine your interaction model
AI apps come in all shapes and sizes, so begin by clarifying how users interact with AI. The interaction model determines your UX, safety posture, and architecture.
Let's look at three common interaction models: chat, hybrid, and background.

The Chat interaction model requires stricter input filtering, abuse detection, PII protection, conversation memory, and rate limiting to limit abuse.
Due to its controlled inputs, the Background interaction model focuses more on data governance, reproducibility, and audit logs, and less on security protections.
Depending on your app, a Hybrid interaction model may be best, as it balances control with flexibility via structured prompts and strong output validation. These apps often primarily focus on task forms (which mimic the background model) with optional free-text fields (which require the protection of chat apps).
Choose your AI model
It's important to choose a model that fits your needs, budget, and more. Different models excel at different jobs. Here are six key considerations for selecting an AI model.
- Capabilities: coding, math and reasoning, multilingual support, vision, speech, tool use and function calling, JSON mode, and long context.
- Constraints: context window, output determinism, safety filters, cost per 1,000 tokens, average latency, and tail latency (p95/p99).
- Quality vs. speed: combine a “smart” model for complex tasks with a “fast” model for autocomplete, rewriting, and routing.
- Closed vs. open: closed (enterprise SLAs, better evaluation performance) versus open-source (control, privacy, on-premises, and cost-efficiency through quantization).
- Fine-tuning and adapters: use fine-tuning for brand tone or domain-specific jargon; prioritize retrieval (RAG) for freshness; combine both approaches when necessary.
- Evaluation: conduct A/B tests and task-specific evaluations before finalizing; assess utility, factuality, and safety.
As models continue to develop, the choices will change. These six considerations, however, can guide you away from or towards a particular model.
Select your provider
The core experience of any AI app is powered by a trusted provider. While this space is still expanding, it's critical to identify your core needs as you evaluate the existing providers.
Let's start with a broad funnel and narrow it down to find a provider that fits your needs.

The options continue to expand, but there are many popular choices today, including: OpenAI, Anthropic, Google Cloud Vertex AI, AWS Bedrock, Azure OpenAI, Together AI, Groq, and Replicate.
1. Do the options meet your infrastructure needs?
Next, narrow down the list by identifying the features you need. Pay special close attention to:
- Centralized keys
- Caching
- Rate limits
- Routing
2. Which features are core to your experience?
Your answer to this question is determined by your interaction model. Consider your needs for streaming, tool use/function calling, JSON mode, batch calls, vision/audio integrations, eval tooling, usage analytics, and spend controls.
Think optimistically and remove any providers from your list who don't meet your app requirements if your app succeeds.
3. Where do your users live?
The location of your users is a critical factor in selecting an AI provider. Consider the following:
- Latency: The distance between your users and the AI provider's servers can impact response times and overall user experience.
- Data residency: Ensure that the provider's servers are located in regions where your users' data is stored and processed.
- Data sovereignty: Consider the legal and regulatory requirements of your users' data, such as GDPR or CCPA.
4. What enterprise needs do you have?
As you move into production, you'll need your provider to have preexisting infrastructure and support for your enterprise needs. Key considerations include SLAs, uptime, data retention and residency, SOC2/ISO, PII handling, model governance, and support.
Evaluate reasoning strategies
Throughout your application, implement reasoning strategies that match the task complexity, latency, and budget. Each application may require a different combination of these strategies.
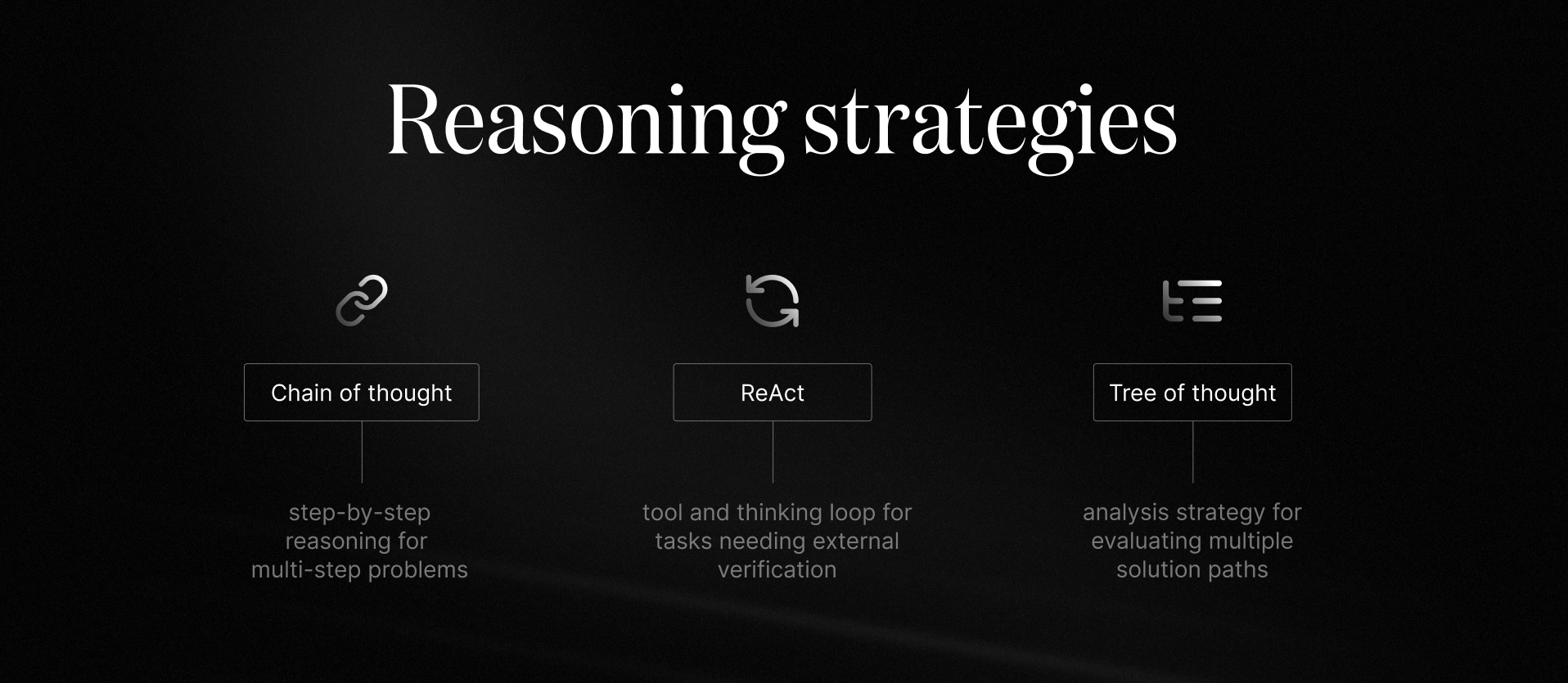
As a general rule, favor structured prompting and hidden scratchpads over exposing raw thought processes for the best UX.
1. Chain of thought
This strategy prompts the model to reason step-by-step internally to solve multi-step problems. It's particularly useful for complex reasoning, math logic, or multi-step planning where decomposition helps.
Implementation tips
- Hide verbose reasoning: Encourage internal deliberation but return only concise, structured answers to users for the best UX (i.e., avoid logging verbatim reasoning).
- Use self-consistency: For harder problems, use the self-consistency pattern (i.e, sample multiple times and return the majority opinion).
2. ReAct
The ReAct strategy involves a loop where the model alternates between thinking and using tools (search, code, DB queries). It's particularly useful for tasks needing external information, tool calls, browsing, or verification.
Implementation tips
- Maintain structure: design a clear tool schema, enforce JSON outputs, handle timeouts, and implement retry logic.
- Log properly: when debugging, log tool inputs and outputs, not the model’s private reasoning.
- Prevent loops: set a max limit for the number of iterations to prevent loops.
3. Tree of thought
This strategy explores multiple reasoning paths as a tree and selects the best branch. It's best for creative generation, hard reasoning puzzles, and evaluating queries across a broad range of alternatives.
Implementation tips
- Know the tradeoffs: this strategy typically carries higher latency and cost.
- Impose constraints: use beam width, depth limits, and intermediate scoring along with aggressive caching and early stopping to control costs.
Set up observability
As with any production system, observability is critical for monitoring, debugging, and optimizing your AI app. Instrument everything from (sanitized) prompts, to your model and version, parameters, token counts, latency, tool calls, user/session IDs, and outcomes.
Implement spans for various stages such as prompt construction, retrieval, model calls, tools, and post-processing. This setup allows for effective bottleneck analysis and aids in regression debugging.
As you make changes to your application, maintain golden datasets and conduct offline evaluations. Additionally, monitor online metrics like click-through rate (CTR), task success, and user satisfaction to direct future app improvements.
Current observability tools
- LangSmith, Langfuse, Helicone, Phoenix (Arize), OpenLLMetry for tracing, dashboards, and feedback
- Built-in gateway analytics (e.g., Vercel AI Gateway, OpenRouter) for rate limits, cache hit rates, and error diagnostics
- LangGraph or similar orchestration can emit rich traces for multi-step flows
Follow key AI patterns
While similar to traditional software, AI applications must consider the unique challenges of large language models (LLMs).
1. Implement guardrails
Add guardrails to keep users safe, protect data, and preserve brand trust. Guardrails include:
- Input protection: prompt-injection and jailbreak filters, URL allowlists/denylists, PII detection/redaction, file-type and size limits.
- Output control: JSON schema validation, grammar-constrained decoding, allowlists for actions, toxicity/PII/factuality checks.
- Policy engine: encode business rules (what the assistant can/can’t do), approval steps for high-risk actions, and human review queues.
Always add guardrails for customer-facing UIs and be stricter for agentic tools that can take actions (e.g., send emails, execute code, etc.).
2. Maintain uptime
Especially in such a new space that requires such heavy infrastructure interaction, design for spikes and provider hiccups.
Build retry logic into your application with exponential backoff, being careful to cap attempts. When possible, prefer idempotent operations.
Consider per-step and end-to-end timeouts under load, favoring graceful degrades (i.e., shorter context, simpler model). When possible, use multi-region endpoints to improve availability and reduce latency.
3. Enable fallback models
Avoid single points of failure by defining a secondary model from a different provider with comparable capability and output format. To aid a multi-model system, normalize outputs with schemas.
Switch to your secondary model based on errors, latency thresholds, or dynamic quality signals.
4. Maintain consistency for ingestion
Your data should be consistent across all models to ensure accurate and reliable results.
- Chunking: split docs by structure (headings, paragraphs) with overlap to preserve context. Tune chunk size to your task (e.g., 300–800 tokens).
- Embeddings + vector DB: store chunks with metadata (source, section, permissions) for semantic retrieval. Options include Pinecone, Weaviate, Qdrant, Milvus, Chroma, pgvector.
- Retrieval quality: hybrid search (semantic + keyword), reranking, deduplication, and freshness indexing. Respect access controls at query time.
- Pipelines: scheduled crawls, webhooks for updates, and validation to prevent toxic or private content from entering the index.
5. Consider memory management
The ability of LLMs is often proportional to their context. When possible, retain memory in your application across interactions while protecting privacy.
Simple approaches
The easiest (and most expensive) approach is to store the full conversation history. However, this can lead to drift and privacy concerns, so consider a windowed approach (e.g., the last N messages, where N is tuned based on context budget and task complexity).
Advanced approaches
For more complex scenarios, consider the following strategies:
- Summarized memory: generate rolling summaries with salient facts, entities, and decisions; periodically refresh to prevent loss.
- Entity/slot memory: track canonical facts about people, projects, preferences in a structured store.
- Vector memory: index conversation snippets and retrieve top-k relevant moments via embeddings (RAG over chats).
Memory raises important privacy concerns. At a minimum, let users view, edit, or reset memory to provide visibility and control. Apply conservative TTLs to prevent drift and ensure data freshness and encrypt memory at rest and in transit.
Conclusion
I trust this guide provides a solid foundation for building robust, modern AI applications. The world of AI is vast and ever-evolving. As we continue to push the boundaries of what's possible, prioritize understanding the underlying challenges, patterns, and methodologies to adapt as new tools emerge.
If you enjoy these types of engineering challenges, explore a career at Resend to join our team. Thanks for reading!